Project Reactor学习--集合Operator
Reactor中,集合类Operator应用于包含多个元素的Flux上,功能和Java 8 Stream中同名函数基本一致。可以分为如下几类:
- 判断元素是否满足条件,如all、any、hasElement等。
- 过滤器filter。
- 排序sort。
- 去重distinct、distinctUntilChanged。
- 分组group。
- 映射map、flatMap。
- reduce。
- 转换求值并结束Flux的操作,如collect、collectList、count等操作。
all
all接收一个Predicate类型的参数,使用该Predicate对Flux中所有的元素进行判断,如果所有元素都满足Predicate的判断,则返回true,否则返回false。判断时使用短路策略,即如果有一个元素不满足要求,立刻返回false,后面的元素不用再判断了。
例子如下:
public class AllOperator {
public static void main(String[] args) {
Flux<Integer> flux = Flux.range(0, 10).log();
Predicate<Integer> allSmallerThan10 = integer -> integer < 10;
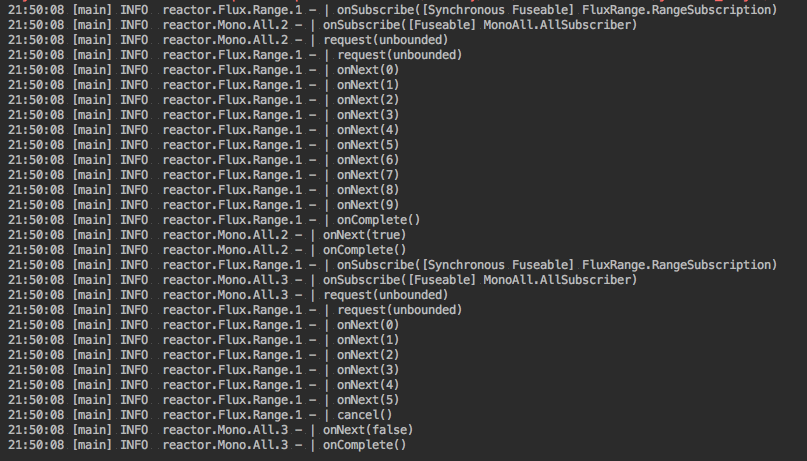
flux.all(allSmallerThan10).log().subscribe();
Predicate<Integer> allSmallerThan5 = integer -> integer < 5;
flux.all(allSmallerThan5).log().subscribe();
}
}
运行时注意观察flux.range的onNext,注意第二次subscribe时,数据在onNext(5)之后就不再满足要求,立刻短路掉了。
any
any和all类似,区别在于any只要求至少有一个元素满足Predicate的要求即返回true。判断时也使用短路策略,即只要发现有一个元素满足要求,立刻返回ture,不再对剩余元素进行判断。
hasElement
这个操作对于null元素返回false,同时基于any。
hasElement(T value) 等价于any(t -> Objects.equals(value, t))。
filter和filterWhen
filter接收一个Predicate参数,使用这个Predicate对元素进行判断,不满足条件的元素都会被过滤掉,满足条件的元素会立刻触发emitted返回给Subscriber。
filterWhen的过程类似,不过将emitted这一步修改为放入buffer中,直到流结束将整个buffer返回。
看代码更直观:
public class Filter {
public static void main(String[] args) {
Flux<Integer> just = Flux.range(1, 10);
/**
* filter的过程为:
* req(1)---> <predicate>--true-->emitted返回元素给Subscriber-->req(1)... 不断循环这个过程直到Flux结束
* |
* false
* |-->drop-->req(1)...
*/
filter(just);
/**
* filterWhen的过程类似,不过将emitted这一步修改为
* 放入buffer中,直到流结束将整个buffer返回
*/
filterWhen(just);
}
private static void filter(Flux<Integer> just) {
StepVerifier.create(just.filter(integer -> integer % 2 == 0).log())
.expectNext(2)
.expectNext(4)
.expectNext(6)
.expectNext(8)
.expectNext(10)
.verifyComplete();
}
private static void filterWhen(Flux<Integer> just) {
StepVerifier.create(just
.filterWhen(v -> Mono.just(v % 2 == 0)).log())
//一次性返回
.expectNext(2, 4, 6, 8, 10)
.verifyComplete();
}
}
sort
sort分为无参数和接收Comparator参数两种。无参数sort要求元素必须实现Comparable接口,接收Comparator参数sort使用接收到的Comparator对元素进行排序。需要注意的时,如果Flux是无限的,sort操作会导致OOM。
distinct和distinctUntilChanged
distinct底层使用HashSet去重,并且保留重复元素中的最后一个元素。
distinctUntilChanged底层也使用HashSet去重,但是只去掉连续出现的重复元素,并且只保留其中第一个元素,如果重复元素不连续出现,则不会被去重。
如下例子:
public class Distinct {
private static Person lijiaming1 = new Person(1, "lijiaming", 17);
private static Person lijiaming2 = new Person(1, "lijiaming", 34);
private static Person xiaowenjie = new Person(2, "xiaowenjie", 35);
public static void main(String[] args) {
Flux<Person> just = Flux.just(
lijiaming1,
lijiaming2,
xiaowenjie,
lijiaming1);
//使用HashSet去重,重复元素中保留最后一个
distinctByHashSet(just);
//去掉连续重复的元素,只保留其中第一个元素
distinctUntilChanged(just);
}
private static void distinctByHashSet(Flux<Person> just) {
StepVerifier.create(
just.distinct())
.expectNext(lijiaming2)
.expectNext(xiaowenjie)
.verifyComplete();
}
private static void distinctUntilChanged(Flux<Person> just) {
StepVerifier.create(
just.distinctUntilChanged())
.expectNext(lijiaming1)
.expectNext(xiaowenjie)
.expectNext(lijiaming1)
.verifyComplete();
}
/**
* 用于被去重的类,由于使用HashSet进行去重,所以需要重写hashCode和equals方法
* 当id相同时即认为两个实例相同
*/
private static class Person {
private long id;
private String name;
private int age;
public Person(long id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return id == person.id;
}
@Override
public int hashCode() {
return (int) (id ^ (id >>> 32));
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
}
运行以上程序,StepVerifier正常结束。
group分组
类似于SQL语句中groupby分组语句。如下例子根据性别分组并计算总数:
public class GroupBy {
public static void main(String[] args) {
Flux<Person> persons = Flux.just(
new Person("A", 0),
new Person("B", 0),
new Person("c", 1),
new Person("d", 1),
new Person("X", 2)
);
groupByGender(persons);
}
private static void groupByGender(Flux<Person> persons) {
//根据性别分组
Flux<GroupedFlux<Integer, Person>> groups = persons.groupBy(person -> person.gender);
groups.flatMap(
groupedFlux ->
//根据性别进行数量计算总数
Mono.just(groupedFlux.key())
.zipWith(groupedFlux.count()))
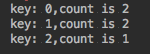
.map(keyAndCount -> "key: " + keyAndCount.getT1() + ",count is " + keyAndCount.getT2())
.subscribe(System.out::println);
}
/**
* 用于被去重的类,由于使用HashSet进行去重,所以需要重写hashCode和equals方法
* 当id相同时即认为两个实例相同
*/
private static class Person {
private String name;
//性别:0为男,1为女,2位Unkown
private int gender;
public Person(String name, int gender) {
this.name = name;
this.gender = gender;
}
public String getName() {
return name;
}
public int getGender() {
return gender;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", gender=" + gender +
'}';
}
}
}
运行结果如下:
映射
map
map操作将一个Flux中的元素依次挨个转换另外的元素,即将源元素作为输入,进行某种计算,将计算结果作为Flux的元素返回给Subscriber。计算时,可以根据源元素的值进行计算,也可以完全忽略源元素。如下例子:
public class MapOperator {
public static void main(String[] args) {
//不根据源元素映射
Flux.range(0, 10)
//无论源元素的值是什么,都映射为硬编码的值
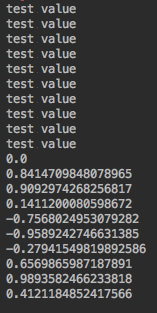
.map(integer -> "test value")
.subscribe(System.out::println);
//根据源元素,映射为其sin值
Flux.range(0, 10)
.map(integer -> Math.sin(integer))
.subscribe(System.out::println);
}
}
输出如下:
flatMap
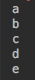
如果一个Flux中的元素类型为Publisher,即Flux中每个元素都是一个响应式流时,flatMap可以将这些元素中的流拼接起来,作为一个流返回。如下例子将字符串拆分,并求得不重复的字母。
public class FlatMapOperator {
public static void main(String[] args) {
Flux<String> flux = Flux.just("a,b,c", "b,c,d", "a,c,d", "a,d,e")
//每个元素都是一个Flux
.map(str -> Flux.fromArray(str.split(",")))
//展开为一个Flux流
.flatMap(stringFlux -> stringFlux);
Flux<String> distinct = flux.distinct();
distinct.subscribe(System.out::println);
}
}
输出如下:
reduce
将流中所有元素反复结合起来,来得到一个值,可以使用reduce。如下求和例子:
public class ReduceOperator {
public static void main(String[] args) {
Flux<Integer> source = Flux.range(0, 100);
//使用迭代方式求和
final AtomicInteger sum = new AtomicInteger(0);
source.subscribe(integer ->
sum.getAndAdd(integer)
);
System.out.println(sum.get());
//reduce方式求和
source.reduce((i, j) -> i + j)
.subscribe(System.out::println);
//reduce方式求和,并且指定reduce的初始值
source.reduce(100, (i, j) -> i + j)
.subscribe(System.out::println);
}
}